Stata常用数据预处理问题
本文申明
如果本文出现逻辑或者学术错误,请在本页留言或者联系作者邮箱(caoyongzhuo@qq.com[国内邮箱];warnerjulia866@gmail.com[国外邮箱])
虽然Markdown语法优雅且规范,但由于博客采用复杂的显示模式,部分文字或表格会被浏览器转义为较丑样式,后期优化,还请谅解
任何转载复用,请遵守 Creative Commons 国际准则,未经授权禁止商业用途
未对接任何广告,下文推荐的数据分发平台均为作者亲测后推荐,读者可以自行选择阿里云[建议]、腾讯云[建议]、百度云[不建议]等大厂平台
如需广告对接请移步上述邮箱或下述WX号,请说明来意,否则一律拒接
Stata安装
- 本文使用 Stata17 MP 中文和谐版(永久激活序列号)编写,内置常用命令库,如需安装与作者相同版本的Stata或有数据分析、一对一辅导需求,请移步WX号:15624552379
Stata导入数据
[-] 导入方式(为方便示例,都使用Excel数据,不考虑SQL数据库数据)
使用代码导入
- 优点:对于超大型数据(一般是5w以上)的数据来说,使用代码导入更加快速,不易出错
- 缺点:要提前对于Excel数据进行分析整理
使用Stata图形化界面导入
- 优点:对于中小型数据、不懂复杂数据结构的人来说是一种友好方式
- 缺点:不适合超大型数据导入
[-] 示例数据如下(请读者自行下载)
为了博客运转速度不被大型文件拖垮,本文所有数据将全部托管于”七牛云CDN“进行转储并全球分发,请读者自行下载
下载模式:点击加粗或高亮超链接文字跳转下载
特别说明:七牛云CDN的付费挺贵的,希望不要有任何不怀好意之人使用网络下载器或爬虫频繁发起请求,博客安装了IP探针并且和公安联网,访客IP都将被记录存档,每12小时上传云端,如果遇到不法分子恶意请求或攻击,后果自负!
[-] 使用代码方式导入
cd "F:\STATA测试数据" //切换工作目录
clear //清除内存中的数据
set more off //设置结果滚动显示
import excel using "auto示例数据.xlsx", firstrow clear //更多参数请在命令行窗口输入 help import 进行详细语法查看- 工作目录以自己电脑的Excel文件存储地址为准,前三行是stata编码的三部曲
auto示例数据.xlsx是需要导入的文件名,具体以自己的文件名为准firstrow参数是将Excel的第一行作为Stata变量名

clear参数是将目前Stata内存中的数据清楚- import的类型不止Excel一种,具体可以参考手册进行查看,手册查看方式:在命令行窗口输入
help import
[-] 使用Stata图形化界面导入
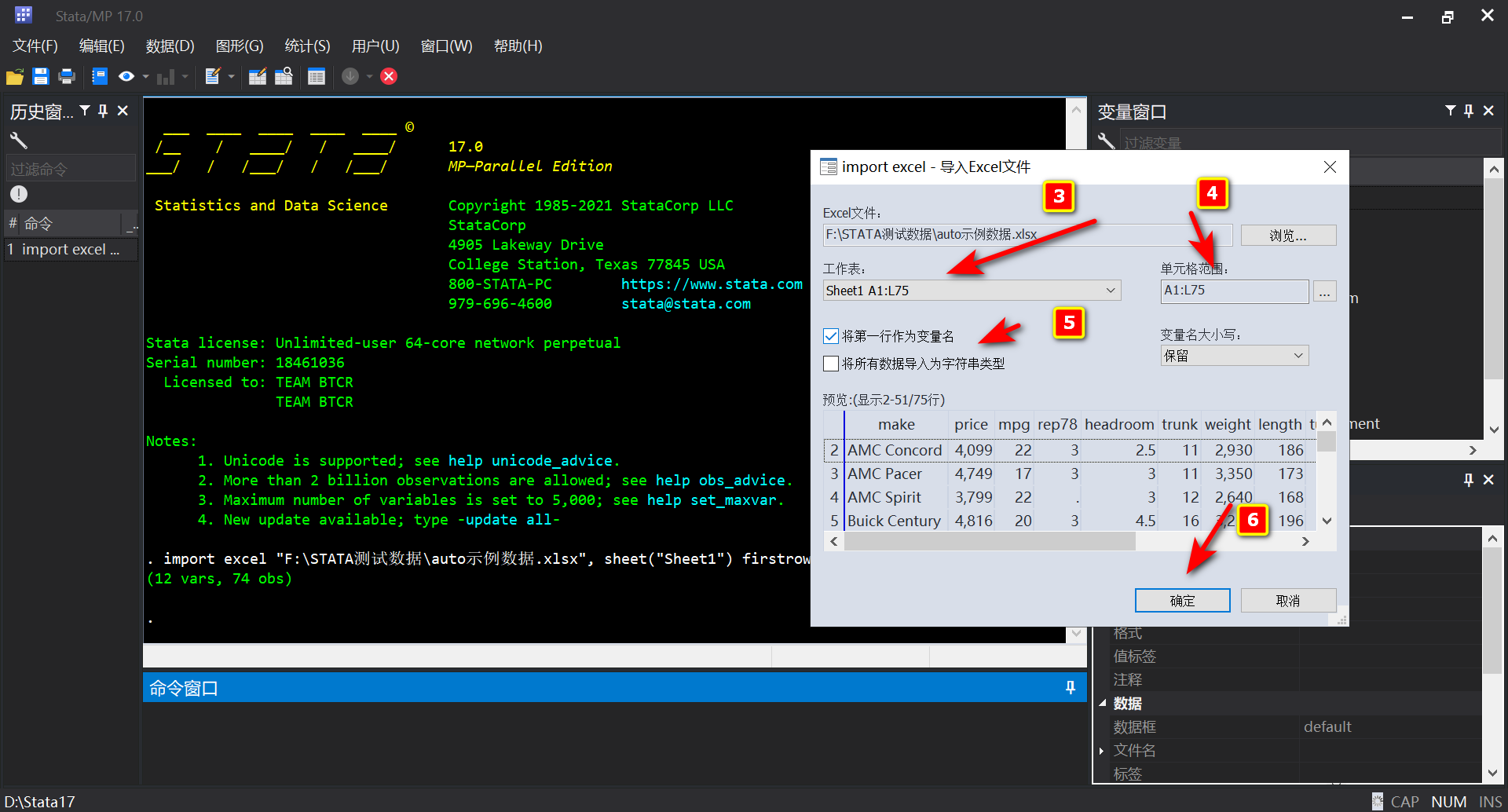
- 打开Stata,在顶部选择”文件“?”导入“?”Excel电子表格“
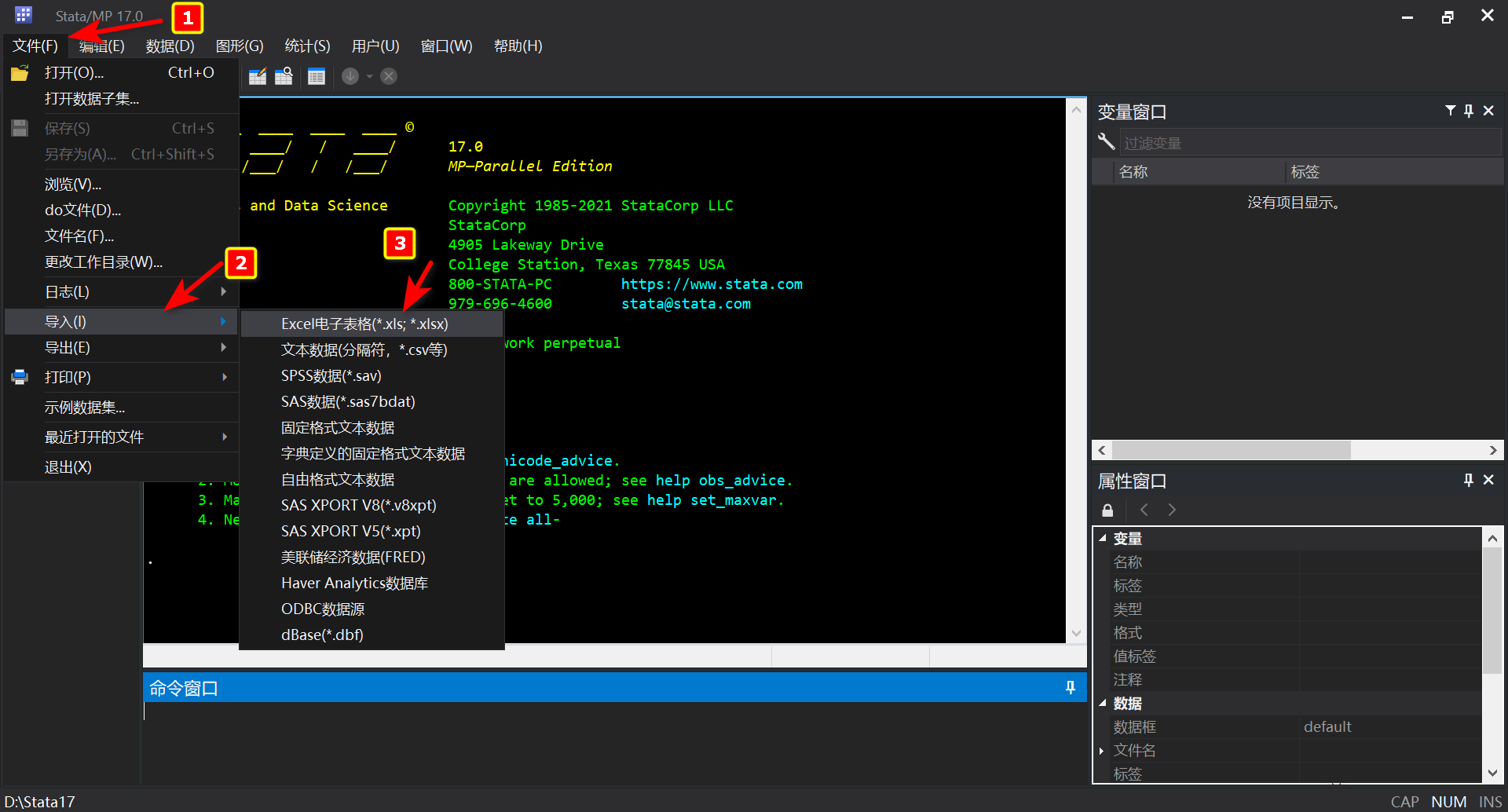
- 在接下来的界面中,选择”浏览“?找到你”存放Excel的目录“?选择”工作表“?选择”单元格范围“?勾选”将第一行作为变量名“?点击”确定“
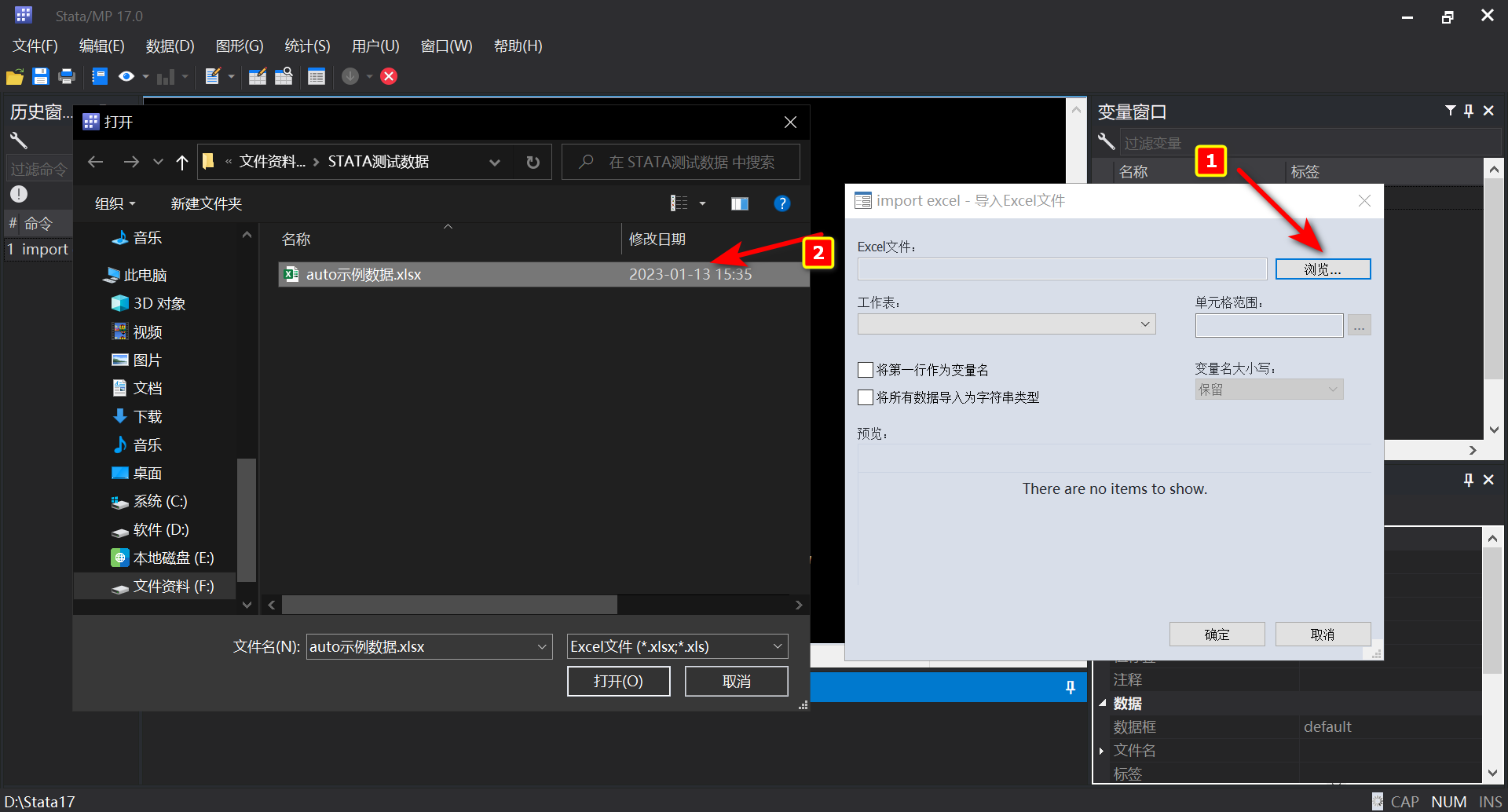
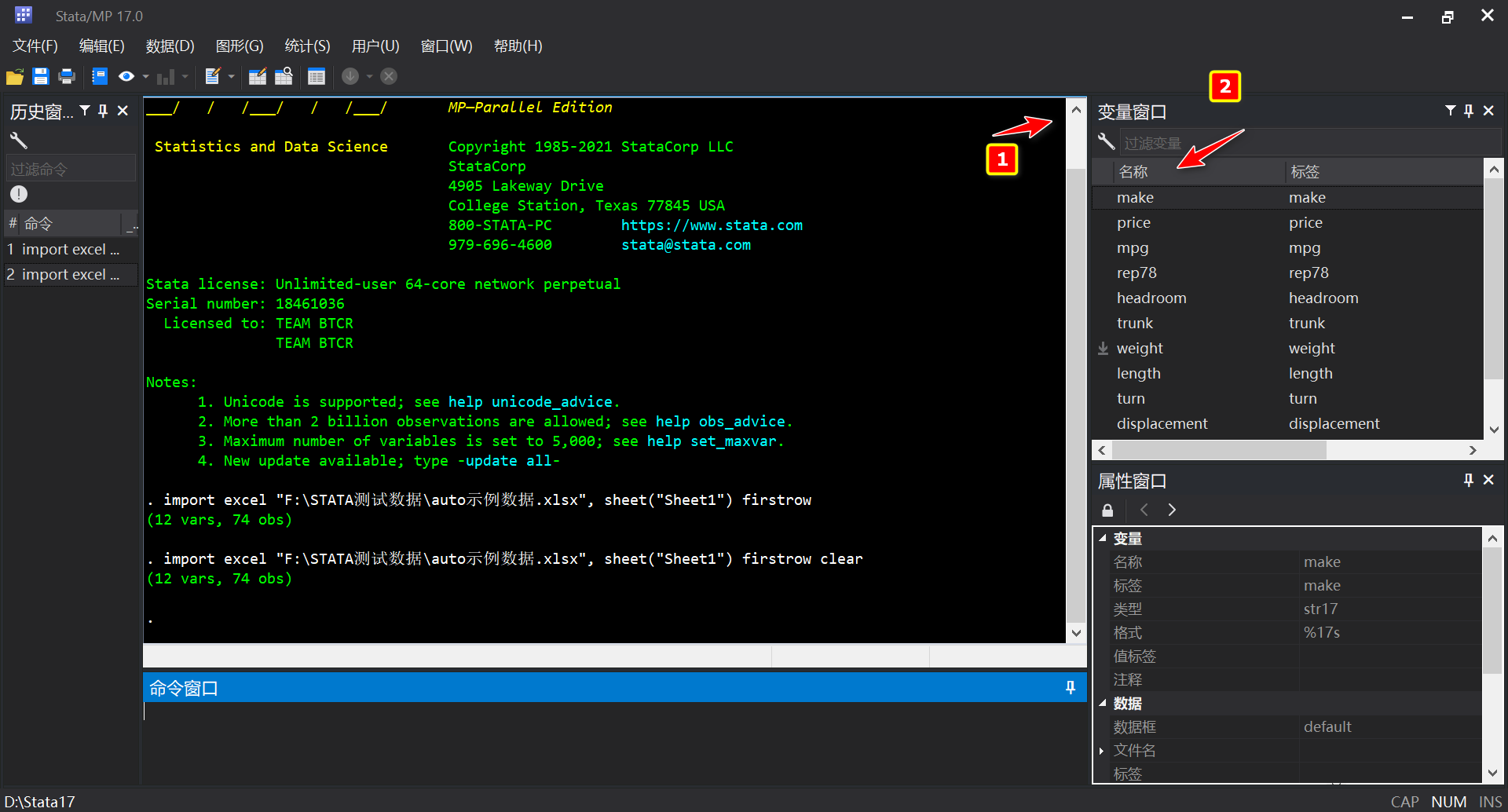
- 此时数据已经导入Stata的数据管理器中,我们可以在右侧的<变量窗口##中看到导入的数据变量名(Excel表的第一行)
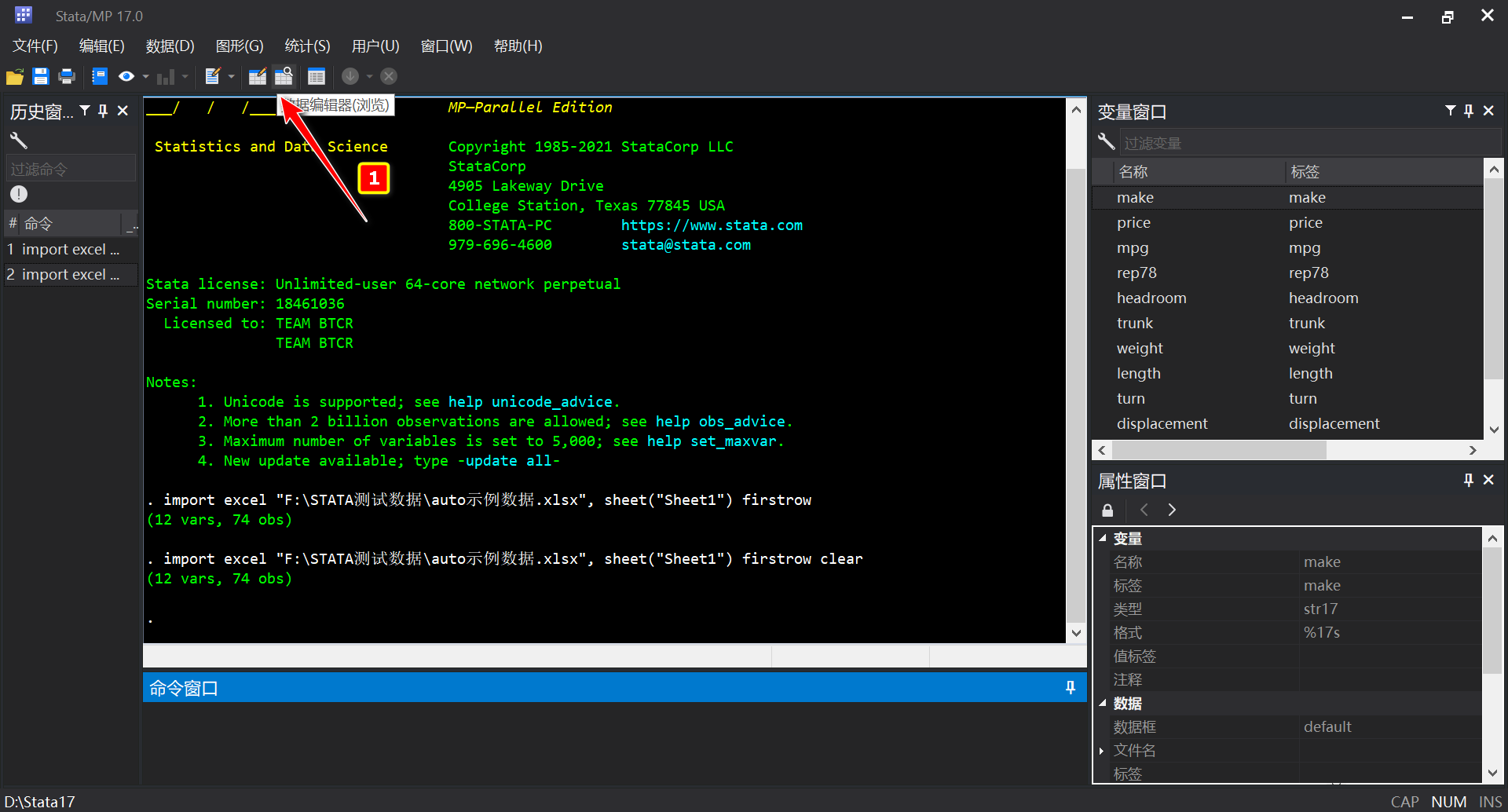
- 如果需要查看每一个变量名所对应的具体数值,我们可以点击Stata上方的数据编辑器
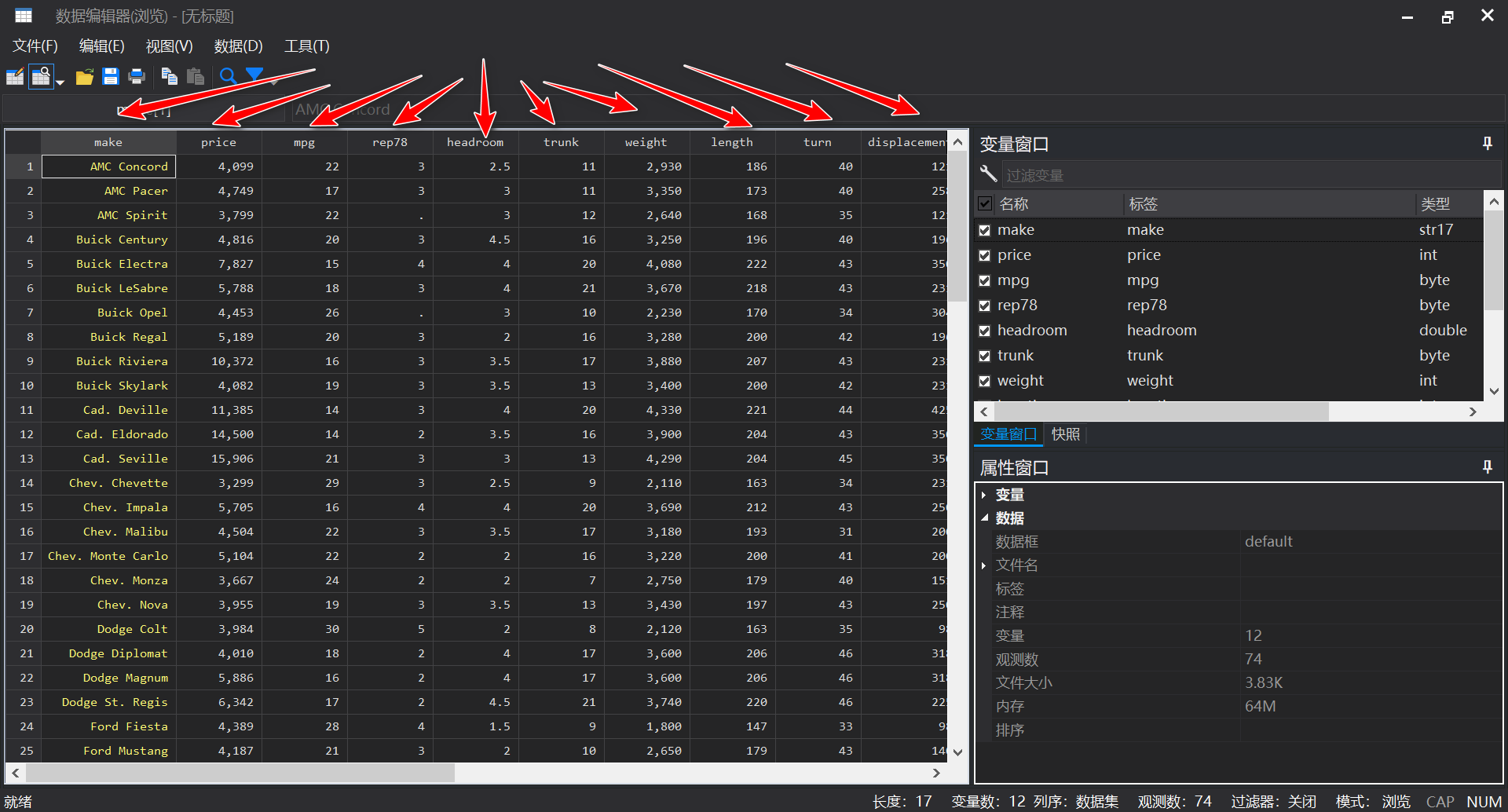
数据类型、数据结构辨析
[-] Stata的常用数据类型
- str --- 字符串类型 (在Stata 17的数据管理器中显示为黄色)
- byte --- 字节类型 (在Stata 17的数据管理器中显示为白色)
- int --- 整形类型 (在Stata 17的数据管理器中显示为白色)
- double --- 数值类型 (在Stata 17的数据管理器中显示为蓝色)
认识基本的数据类型有助于后期在数据预处理过程中如merge、append、duplicates drop等命令的正常运行
[-] Stata的常用数据结构
- 截面数据 --- 作者口诀:多个体,单时间
- 时间序列数据 --- 作者口诀:单个体,多时间
- 面板数据 --- 作者口诀:多个体,多时间
作者在此处使用 山东大学 - 陈强 -《高级计量经济学》中的课件进行阐释,陈强博客地址:http://www.econometrics-stata.com/col.jsp?id=101
- 截面数据
| 省份 | GDP |
|---|---|
| 北京 | 19500.56 |
| 天津 | 14370.16 |
| 河北 | 28301.41 |
| 山西 | 12602.24 |
| 内蒙古 | 16832.38 |
| 辽宁 | 27077.65 |
| 吉林 | 12981.46 |
| 黑龙江 | 14382.93 |
| 上海 | 21602.12 |
| 江苏 | 59161.75 |
| 浙江 | 37568.49 |
| 安徽 | 19038.87 |
| 福建 | 21759.64 |
| 江西 | 14338.5 |
| 山东 | 54684.33 |
| 河南 | 32155.86 |
| 湖北 | 24668.49 |
| 湖南 | 24501.67 |
| 广东 | 62163.97 |
| 广西 | 14378 |
| 海南 | 3146.46 |
| 重庆 | 12656.69 |
| 四川 | 26260.77 |
| 贵州 | 8006.79 |
| 云南 | 11720.91 |
| 西藏 | 807.67 |
| 陕西 | 16045.21 |
| 甘肃 | 6268.01 |
| 青海 | 2101.05 |
| 宁夏 | 2565.06 |
| 新疆 | 8360.24 |
- 时间序列数据
| 年份 | GDP |
|---|---|
| 1994 | 3844.5 |
| 1995 | 4953.35 |
| 1996 | 5883.8 |
| 1997 | 6537.07 |
| 1998 | 7021.35 |
| 1999 | 7493.84 |
| 2000 | 8337.47 |
| 2001 | 9195.04 |
| 2002 | 10275.5 |
| 2003 | 12078.2 |
| 2004 | 15021.8 |
| 2005 | 18366.9 |
| 2006 | 21900.2 |
| 2007 | 25776.9 |
| 2008 | 30933.3 |
| 2009 | 33896.6 |
| 2010 | 39169.9 |
| 2011 | 45361.9 |
| 2012 | 50013.2 |
| 2013 | 54684.3 |
- 面板数据
| 省份 | 年份 | GDP |
|---|---|---|
| 北京 | 1994 | 1145.31 |
| 北京 | 1995 | 1507.69 |
| ... | ... | ... |
| 北京 | 2012 | 17879.4 |
| 北京 | 2013 | 19500.56 |
| 天津 | 1994 | 732.89 |
| 天津 | 1995 | 931.97 |
| ... | ... | ... |
| 天津 | 2012 | 12893.88 |
| 天津 | 2013 | 14370.16 |
| ... | ... | ... |
| 新疆 | 1994 | 662.32 |
| 新疆 | 1995 | 814.85 |
| ... | ... | ... |
| 新疆 | 2012 | 7505.31 |
| 新疆 | 2013 | 8360.24 |
在一般情况下,对于面板数据,我们可以拆分成截面数据和时间序列数据,但是这个过程无法逆向拆分,只可以逆向补充。原因是面板数据作为多个体、多时间的数据结构来说,想要拆分成截面数据的话,只需要提取单个时间节点的数据;想要拆分成时间序列数据的话,只需要提取单个个体的数据,这是一个十分有趣的过程,在下面我们进行详细介绍。
[-] 面板数据拆分为截面数据
下载数据并导入Stata
** 面板数据拆分截面数据演示
cd "F:\STATA测试数据" //切换工作目录
clear //清除内存中的数据
set more off //设置结果滚动显示
import excel using "1994-2013年分省.xlsx", firstrow clear //导入面板数据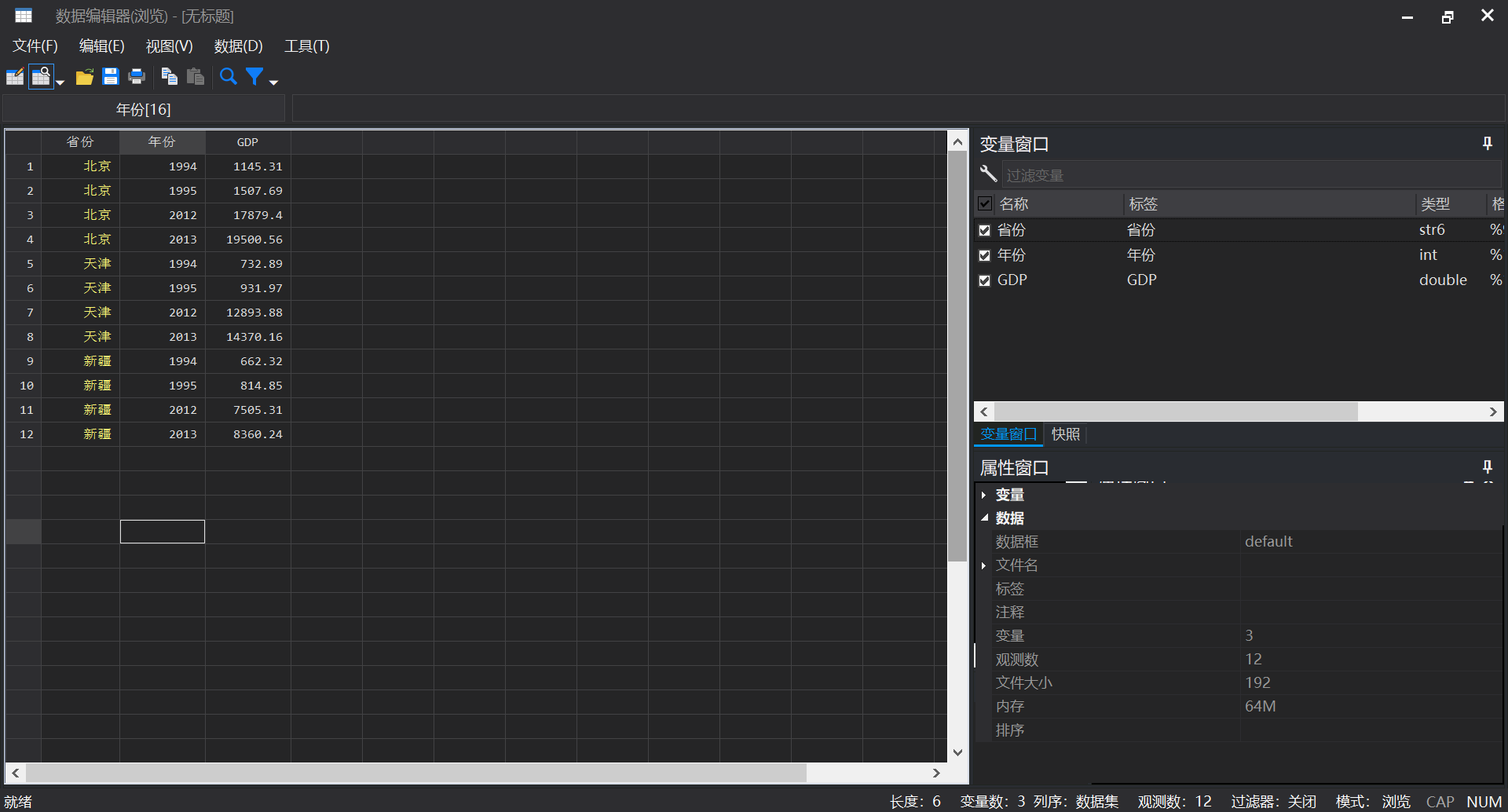
- 我们假设只需要截取1994年的界面数据
keep if 年份 == 1994 //第一种方式,使用keep保留符合要求的数据
drop if 年份 != 1994 //第二种方式,使用drop删除不符合要求的数据此处Markdown语法与Stata语法出现了转义,请读者按照下图第14行代码中的"!="描述<不等于##逻辑判断
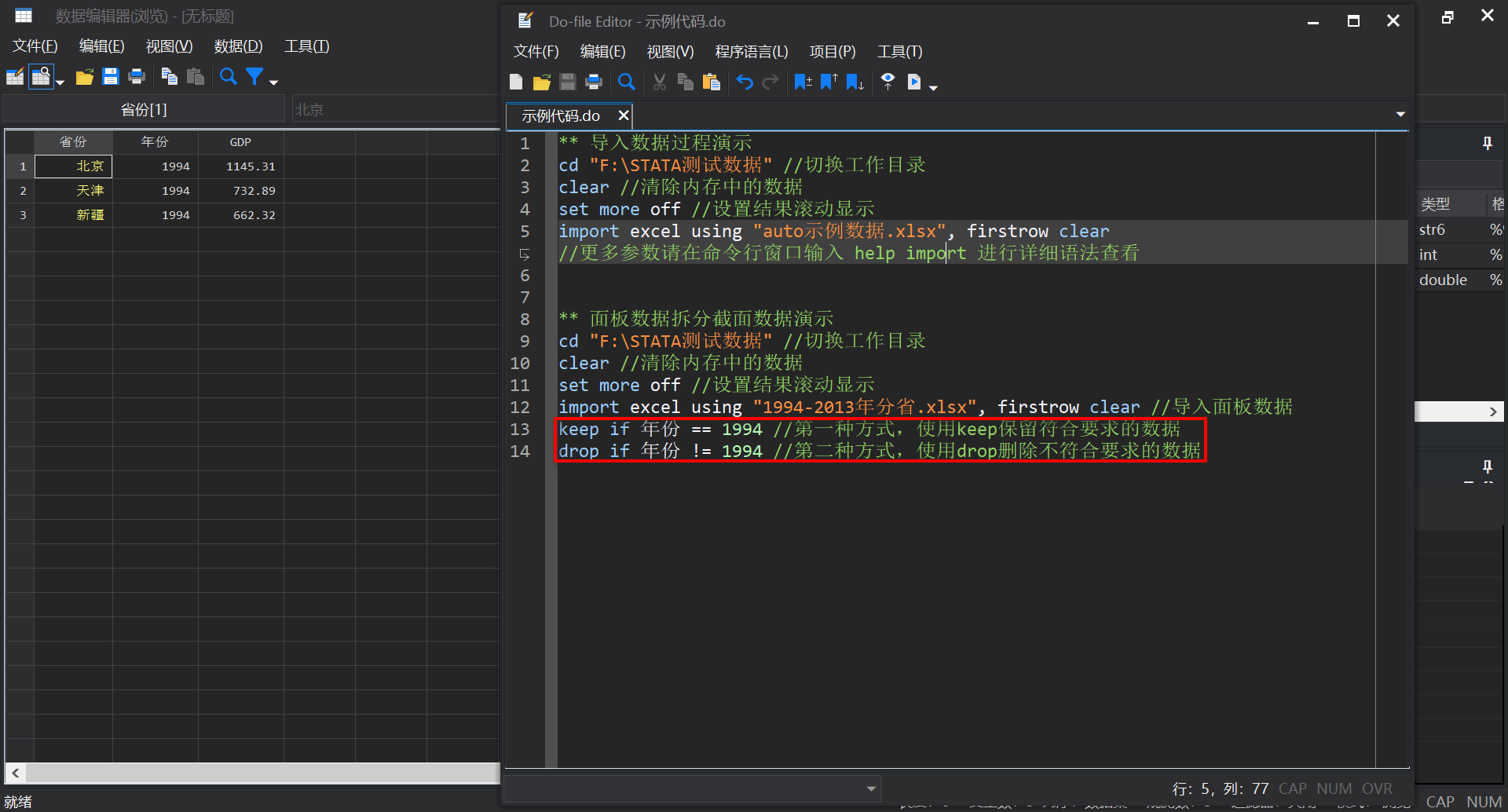
[-] 面板数据拆分为时间序列数据
下载数据并导入Stata
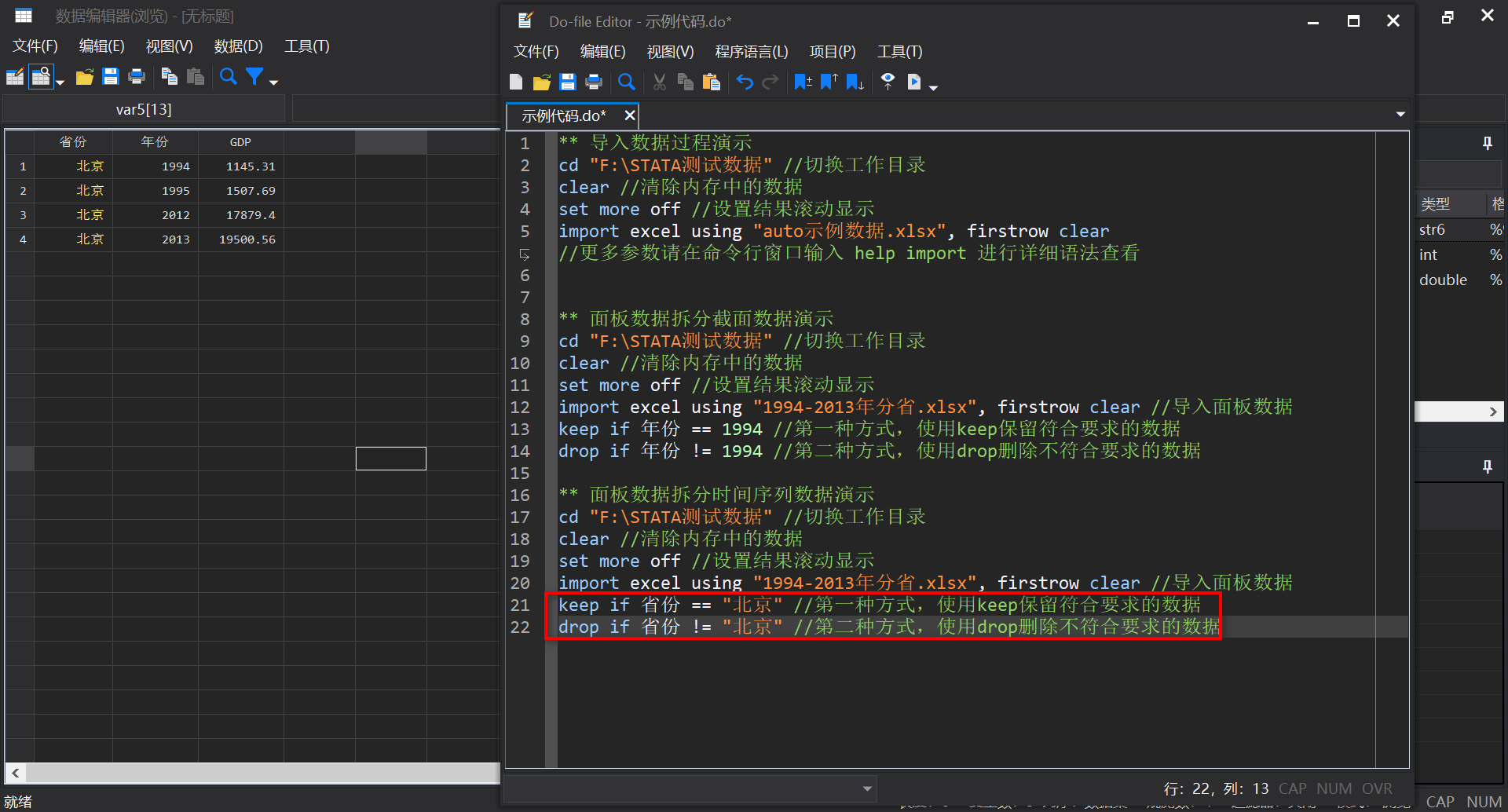
keep if 省份 == "北京" //第一种方式,使用keep保留符合要求的数据
drop if 省份 != "北京" //第二种方式,使用drop删除不符合要求的数据此处Markdown语法与Stata语法出现了转义,请读者按照下图第14行代码中的"!="描述<不等于##逻辑判断
字符串拼接
[-] 原始数据结构
| var1 | var2 | //变量名
% str % str % //数据类型
[-] 语法
gen new_var = var1 + var2
[-] 示例原始数据
| var1 | var2 |
| 12345| 5678 |
[-] 示例语法
gen sum_string = var1 + var2
[-] 示例结果数据
| var1 | var2 | sum_string | //变量名
| 12345 | 5678 | 123455678 | //变量名所对应的数值
字符串拆分
[-] 原始数据结构
| sum_string |
% str %
[-] 语法
gen new_var = substr(sum_string,m,n)
- m : 从单元格第几个字符开始
- n :从开始字符选择几个字符
- 注意:一个汉字占用2个字符,一个数字占用1个字符
[-] 示例原始数据
| sum_string |
| 12345678 |
[-] 示例语法
gen var3 = substr(sum_string,2,4)
[-] 示例结果数据
| var3 |
| 2345 |
分组求和(单、多层级)
[-] 原始数据结构
数据结构不限
[-] 语法
bysort var1 : egen new_var = sum(var2) // 以var1为分类,对var2分组求和
bysort var1 var3 : egen new_var = sum(var2) // 以var1为一级分类,var3为二级分类,对var2分组求和
- 其中的sum()函数可以更换为count()分组计数、max()分组求最大值
- 其中的new_var变量名换成自己想要的就行
[-] 示例原始数据
| var1 | var2 | var3 |
| 1 | 3 | A |
| 1 | 2 | A |
| 1 | 2 | A |
| 1 | 3 | B |
| 1 | 2 | B |
| 1 | 3 | B |
| 2 | 1 | A |
| 2 | 1 | A |
| 2 | 2 | A |
| 2 | 2 | B |
| 2 | 2 | B |
[-] 示例语法
bysort var1 var3 : egen newvar = count(var2)
[-] 示例结果数据
| var1 | var2 | var3 | new_var |
| 1 | 3 | A | 3 |
| 1 | 2 | A | 3 |
| 1 | 2 | A | 3 |
| 1 | 3 | B | 3 |
| 1 | 2 | B | 3 |
| 1 | 3 | B | 3 |
| 2 | 1 | A | 3 |
| 2 | 1 | A | 3 |
| 2 | 2 | A | 3 |
| 2 | 2 | B | 3 |
| 2 | 2 | B | 3 |