Matlab期末大作业(代码纯享版)
文章地址:https://caoyongzhuo.cn/archives/902
备用地址:https://cloud.tencent.com/developer/article/2200692
代码如下:
%% 初始操作
cd 'F:\MATLAB\已恢复\本地磁盘(E)\caoyongzhuo\test2022_2\test2022_2' % 切换工作目录
ls % 列出当目录文件以确保工作路径选择正确
clc;
clear;
%% 第一问
clc;
clear;
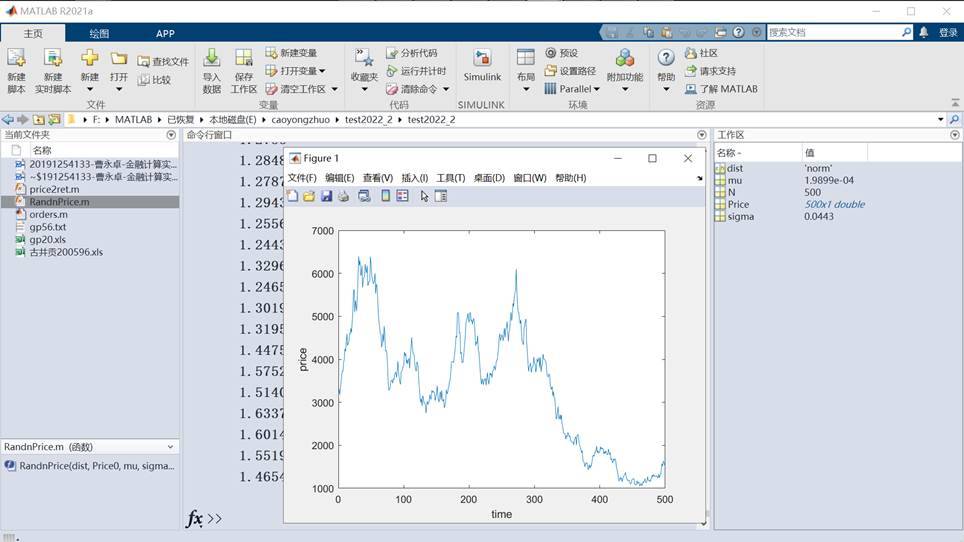
Price = 3080; % 上证A股综合指数价格
mu = 1.051^(1/250)-1; % 上证A股综合指数平均收益率
sigma = 0.7/sqrt(250); % 上证A股综合指数标准差
N = 250*2; % 依据上课作业文件,我们可知一年的交易日为250天,两年极为250*2
dist = 'norm'; % 确定随机的模式(正态分布)
Price = RandnPrice(dist,Price,mu,sigma,N); % 上证A股综合指数预测价格
plot(Price(:,1)); % 行列转换
xlabel('time');
ylabel('price');
%% 第二问
clear % 清楚workspace中的数据文件
clc % 清楚窗口中的所有代码
% 设置时间序列数据
ftsdatas = ascii2fts('data.txt',2,2) % 设置时间序列数据
save ftsdatas.mat %将时间序列数据的mat文件保存在工作目录下
% MACD指标
% 绘制收盘价
load ftsdatas.mat
macdc = macd(ftsdatas)
plot(macdc)
% 绘制开盘价
macdo = macd(ftsdatas,'open')
plot(macdo)
% 威廉指标
wms = willpctr(ftsdatas)
plot(wms) % 绘制wms图像
hold on % 保持绘图窗口保持不变
plot(wms.dates,-80*ones(1,length(wms)),'color',[0.5 0 0],'linewidth',3) % 绘制的是横轴为时间,纵轴为一列,wms长度行的线条
plot(wms.dates,-20*ones(1,length(wms)),'color',[0 0.5 0],'linewidth',3)
hold off %关闭绘图窗口
% RSI技术指标
load ftsdatas.mat
rsi = rsindex(ftsdatas)
plot(rsi)
hold on
plot(rsi.dates,30*ones(1,length(rsi)),'color',[0.5 0 0],'linewidth',2) % 绘制的是横轴为时间,纵轴为一列,rsi长度行的线条
plot(rsi.dates,30*ones(1,length(rsi)),'color',[0 0.5 0],'linewidth',2)
hold off
% OBV指数
load ftsdatas.mat %% 从本地mat文件中调用数据
obv = onbalvol(ftsdatas) %%% 从workspace中调用数据
plot(obv)
% 绘制candle图
load ftsdatas.mat;
candle(ftsdatas)
% 绘制合并图
load ftsdatas.mat;
subplot(2,2,4)
candle(ftsdatas) %%绘制candle图
subplot(2,2,3)
plot(willpctr(ftsdatas))
subplot(2,2,1)
plot(macd(ftsdatas))
subplot(2,2,2)
rsi = rsindex(ftsdatas)
plot(rsi)
hold on
plot(rsi.dates,30*ones(1,length(rsi)),'color',[0.5 0 0],'linewidth',2) % 绘制的是横轴为时间,纵轴为一列,rsi长度行的线条
plot(rsi.dates,30*ones(1,length(rsi)),'color',[0 0.5 0],'linewidth',2)
hold off
%% 第三问
%存放20股票的100天的收盘价
clc
clear
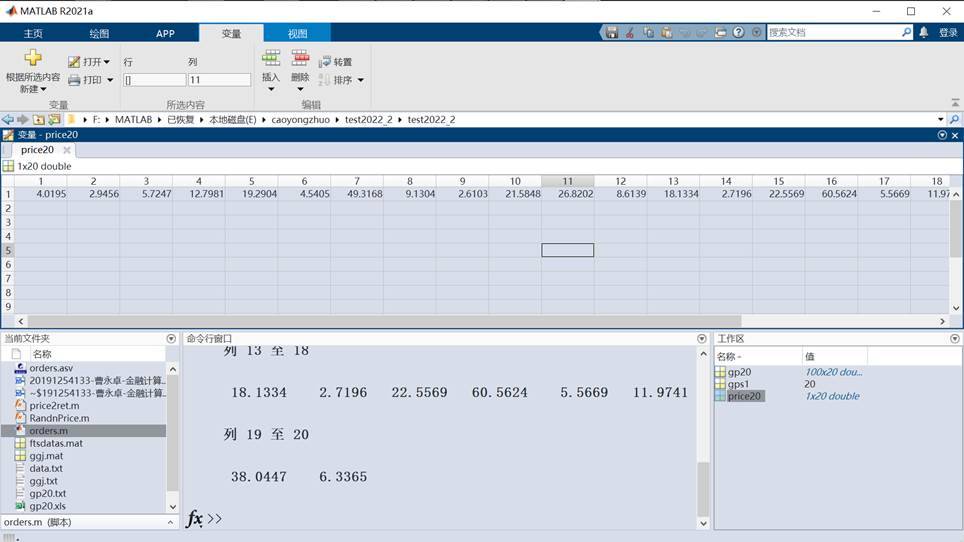
load gp20.txt
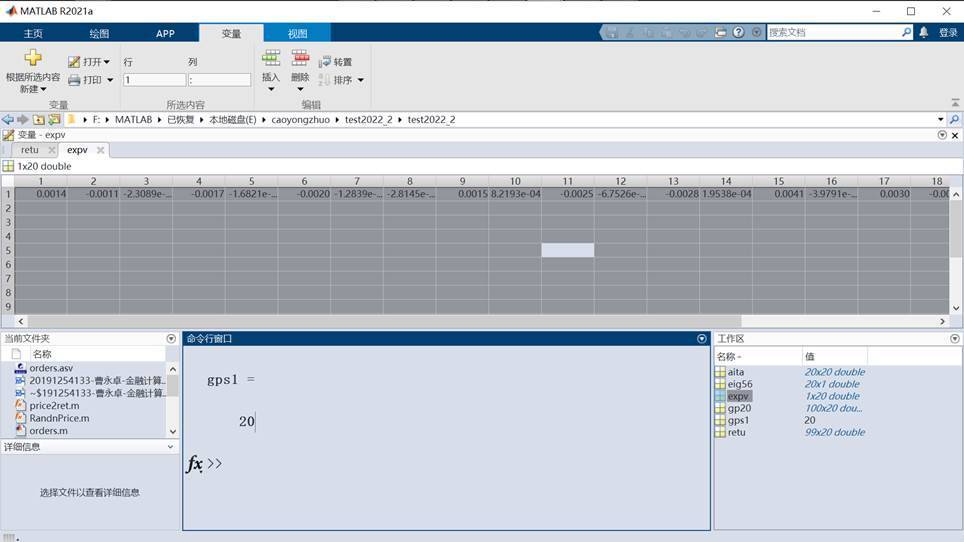
gps1=20
%%1﹣计算期望收益
price20 = mean(gp20)
%%2﹣计算收益率矩阵
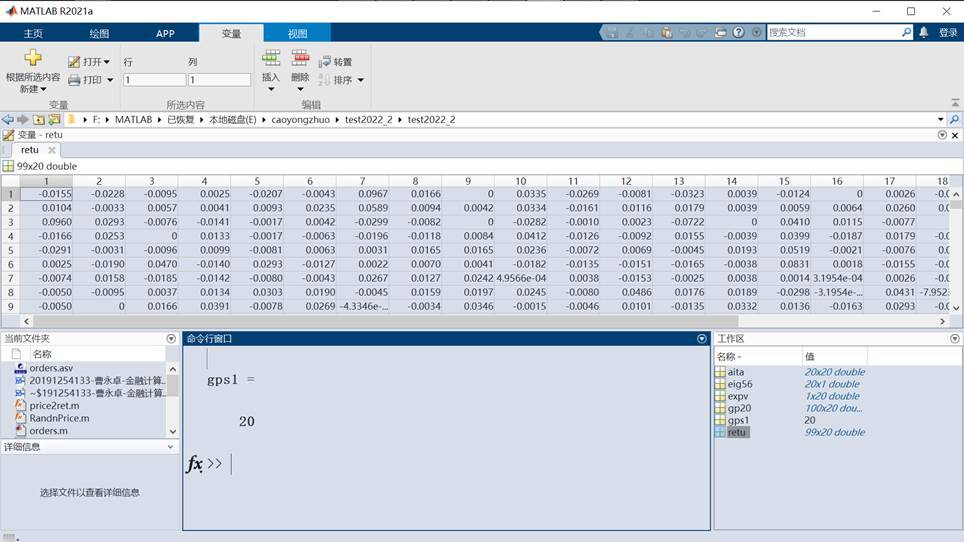
retu =price2ret(gp20);
%%3﹣计算期望收益
expv = mean(retu);
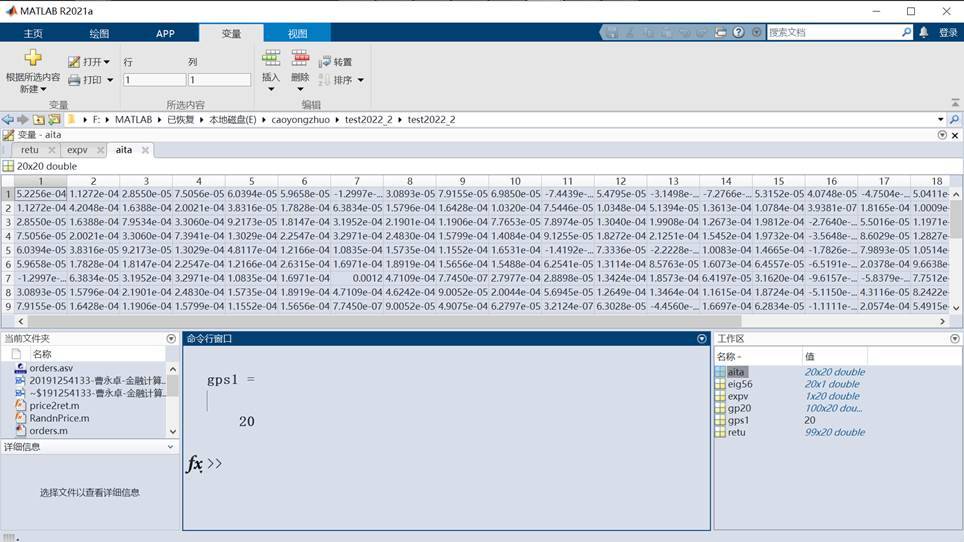
%%%4﹣计算协方差矩阵% aita( X , Y )= sigama ( Xi - X )( Yi - Y ) Pi
aita = cov ( retu );
eig56= eig ( aita );
%协方差矩阵非半正定,进行修正
aita = aita+eye (gps1,gps1)*0.00001;%若非半正定,加很小的数使其为半正定矩阵
%% 第四问
clc
clear %三个资产的投资选择问题
returns=[0.1 0.18 0.15] % 期望收益向量
stds=[0.15 0.25 0.2] %标准差-表示每个资产的波动性
correlations=[1 0.9 0.1;0.9 1 0.4;0.1 0.4 1] %相关系数-对称矩阵
covariances=corr2cov(stds,correlations) %计算协方差矩阵
portopt(returns,covariances,10) %选择10个点
hold on
rand('state',0)
weights=rand(500,3)
total=sum(weights,2) %weights矩阵的行相加
weights(:,1)=weights(:,1)./total %对权重做标准化处理
weights(:,2)=weights(:,2)./total
weights(:,3)=weights(:,3)./total
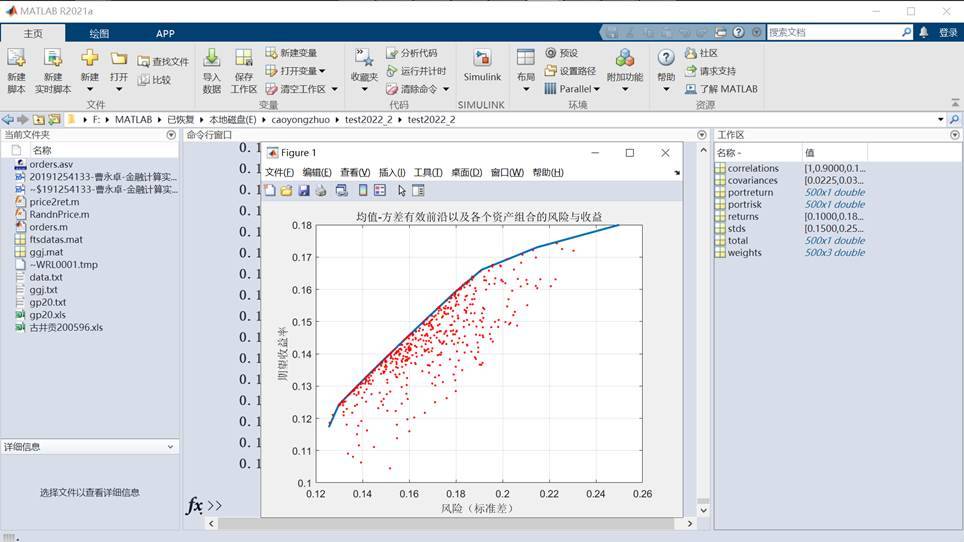
[portrisk,portreturn]=portstats(returns,covariances,weights)
plot(portrisk,portreturn,'.r')
title('均值-方差有效前沿以及各个资产组合的风险与收益')
xlabel('风险(标准差)')
ylabel('期望收益率')
hold off
clc
clear
rand('state',0)
figure
% RandSumOneTest
M=500;
N=3;
% method=1;
% X1=RandSumOne(M,N,method);
X1=rand(M,N)
total1=sum(X1,2) % 按行求和
for i=1:N % 比例 标准化,变成了权重矩阵
X1(:,i)=X1(:,i)./total1;
end
X2=rand(M,N)
total2=sum(X2,2)
for j=1:N
X2(:,j)=X2(:,j)./total2;
end
% method=2;
% X2=RandSumOne(M,N,method);
%预期收益率向量
ExpReturn = [0.1 0.18 0.15];
%协方差矩阵
ExpCovariance = [0.0225000000000000,0.0337500000000000,0.00300000000000000
0.0337500000000000,0.0625000000000000,0.0200000000000000
0.00300000000000000,0.0200000000000000,0.0400000000000000];
%变量初始化
PortRisk1=zeros(M,1);
PortReturn1=zeros(M,1);
PortRisk2=zeros(M,1);
PortReturn2=zeros(M,1);
for i=1:M
[PortRisk1(i), PortReturn1(i)] = portstats(ExpReturn, ExpCovariance,X1(i,:));
[PortRisk2(i), PortReturn2(i)] = portstats(ExpReturn, ExpCovariance,X2(i,:));
end
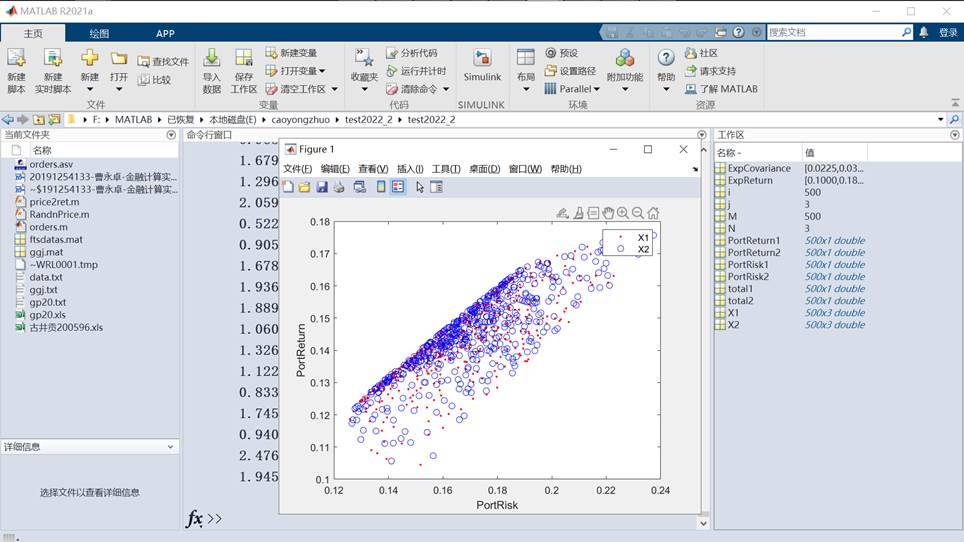
plot(PortRisk1, PortReturn1,'r.')
hold on
plot(PortRisk2, PortReturn2,'bo')
xlabel('PortRisk')
ylabel('PortReturn')
legend('X1','X2')